Context
This project was developed as part of the KIAUMU program. The goal: understand and apply AI music tools to recreate the sound, mood, and production style of a reference track — and deliver an original track that moves from demo quality to studio mastering standard.
Tools used: Sonoteller.ai · Suno · FADR · ElevenLabs · Adobe Audition
Core objectives:
- Reverse engineer a reference track using AI analysis
- Build and test prompts across genres, moods, and instrumentation
- Generate multiple track variants, then refine through stem separation, mixing, and mastering
- Add a consistent DJ narrator voice across all deliverables
Phase 1 — Reverse Engineering the Reference

Every track has a structure that can be decoded. Using Sonoteller.ai, the reference was broken down across six dimensions:
- Structural breakdown — song sections, transitions, arrangement
- Mood & lyrical themes — emotional arc, lyric tone
- Tempo & rhythmic feel — BPM, groove, swing
- Energy curve — build, drop, release points
- Instrument layers — lead, rhythm, texture, bass, percussion
- Vocal character — timbre, register, style
Sonoteller.ai Analysis Result
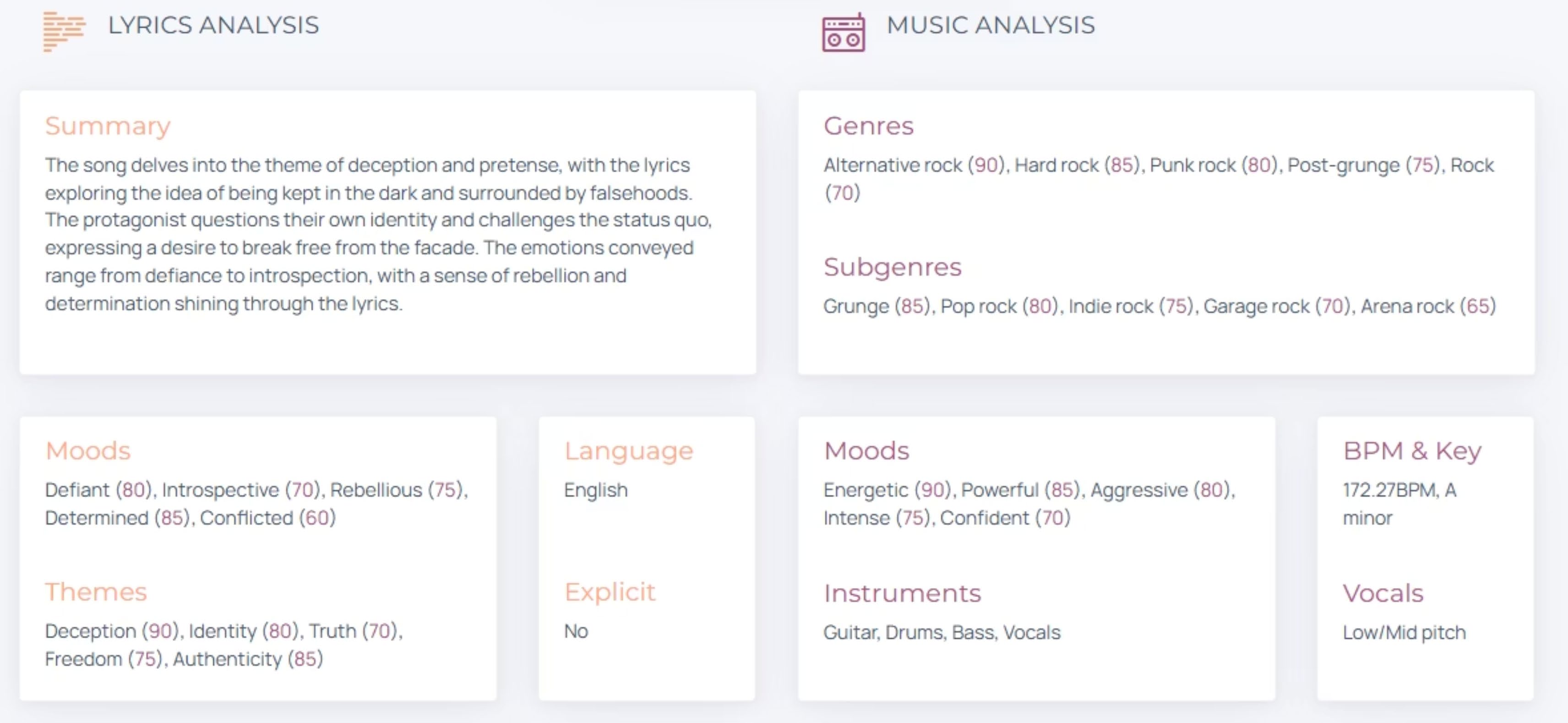
The analysis output provided a structured breakdown used directly to inform the Suno prompt system in Phase 2.
Phase 2 — Prompt Design
Multiple tracks were generated — each with deliberately varied parameters:
Variables tested per track:
- Genres — Rock, Soft Rock, Trip-Hop, Blues, electronically-influenced
- Moods — dark, dreamy, melancholic, energetic, calm
- Instrumentation — distorted guitar, warm bass, soft drums, piano, ambient synths, percussion
- Vocal types — dark male baritone, emotional male lead, soft female, tender female
- Tempo — 90, 120, 122 BPM tested (note: Suno doesn't always hold BPM strictly — structure and style tags proved more reliable)
Shared prompt structure used across all tracks:
| Tag type | Elements |
|---|---|
| Structure | [Intro] [Verse] [Chorus] [Bridge] [Outro] |
| Mood | dark, atmospheric, soft, warm, emotional, dreamy, nostalgic |
| Instruments | distorted guitar, warm bass, soft drums, piano, ambient synth |
| Vocal identity | dark male baritone / soft female / emotional male lead |
Phase 3 — Music Generation with Suno
Shared production targets across all generated tracks:
- Achieve higher production quality — avoid the "demo tape" feel
- Clear vocals, balanced instruments, coherent structure
- Maintain emotional alignment between lyrics and music
Key observations from generation:
- More specific prompts produce more consistent results
- Lyrics should be short and expressive
- Instrument labels significantly influence groove and style
- Mood descriptors change harmony and energy dramatically
Phase 4 — Stem Separation (FADR)
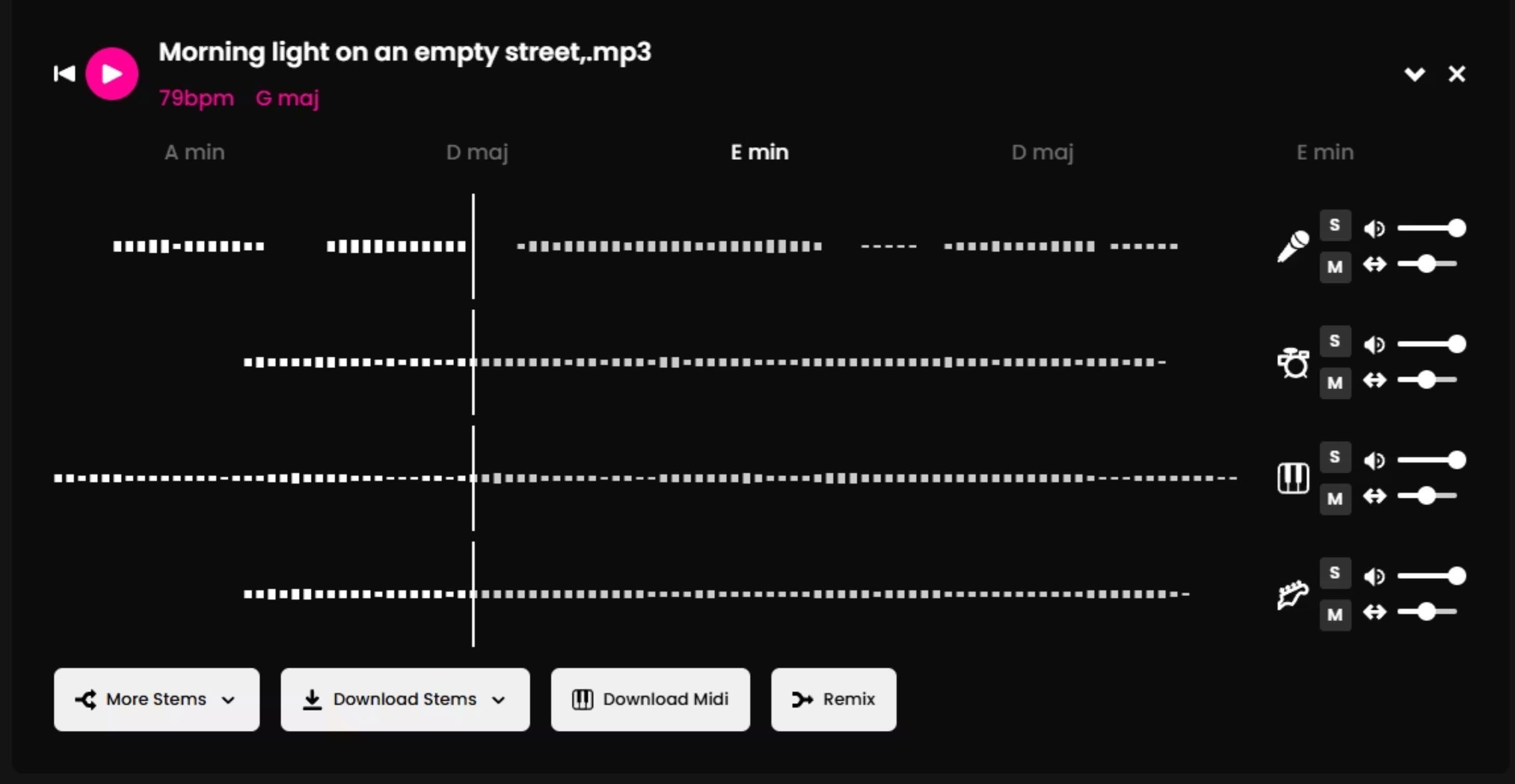
Generated tracks were run through FADR for stem separation — isolating vocals, drums, bass, and melodic elements. This enabled targeted adjustments without affecting the full mix.
Phase 6 — Mixing and Mastering
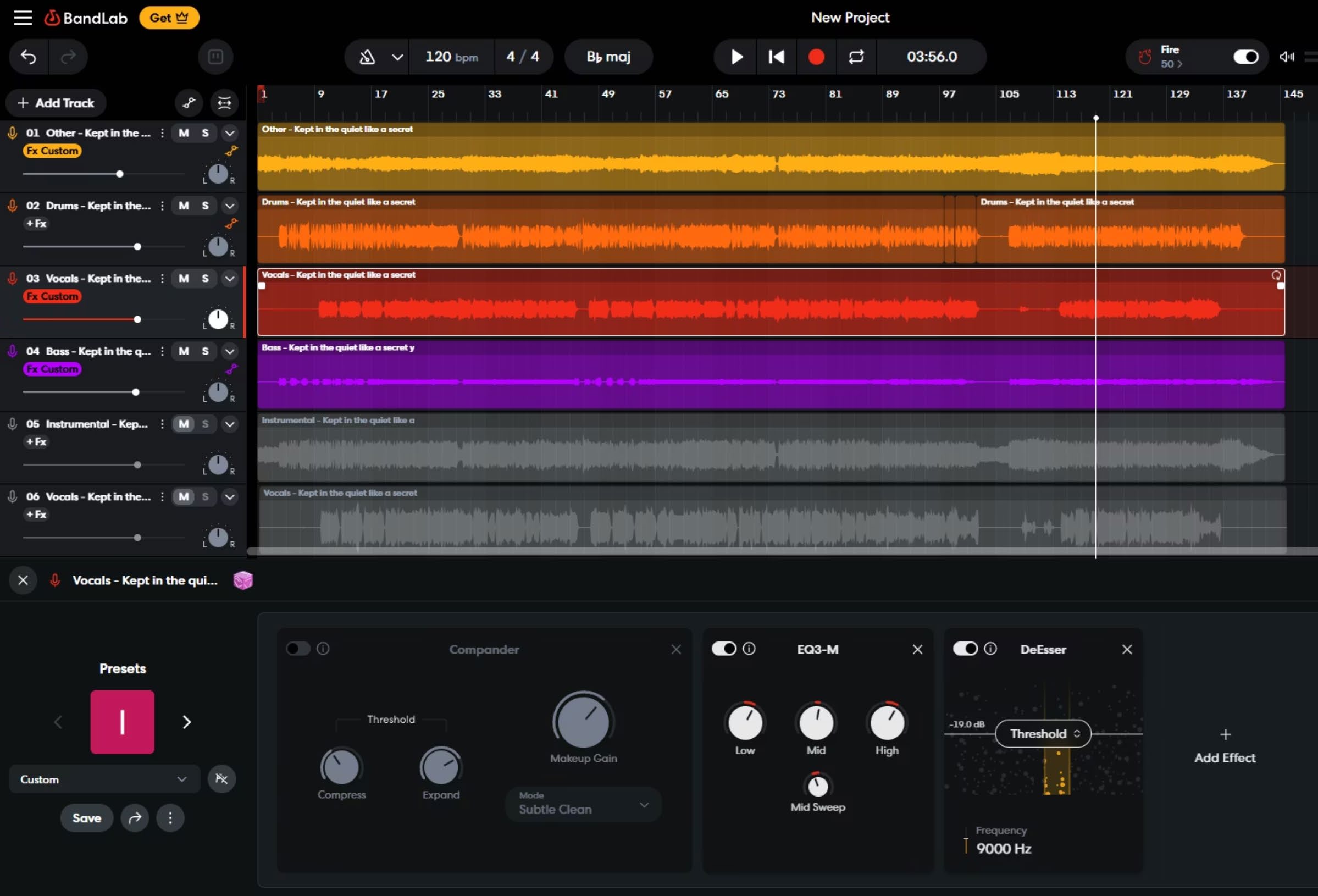
Individual stems were reassembled and processed to reach a studio-mastering quality level. The mixing stage addressed balance, spatial placement, and dynamic range across all instrument layers.
Phase 7 — DJ Voice Setup
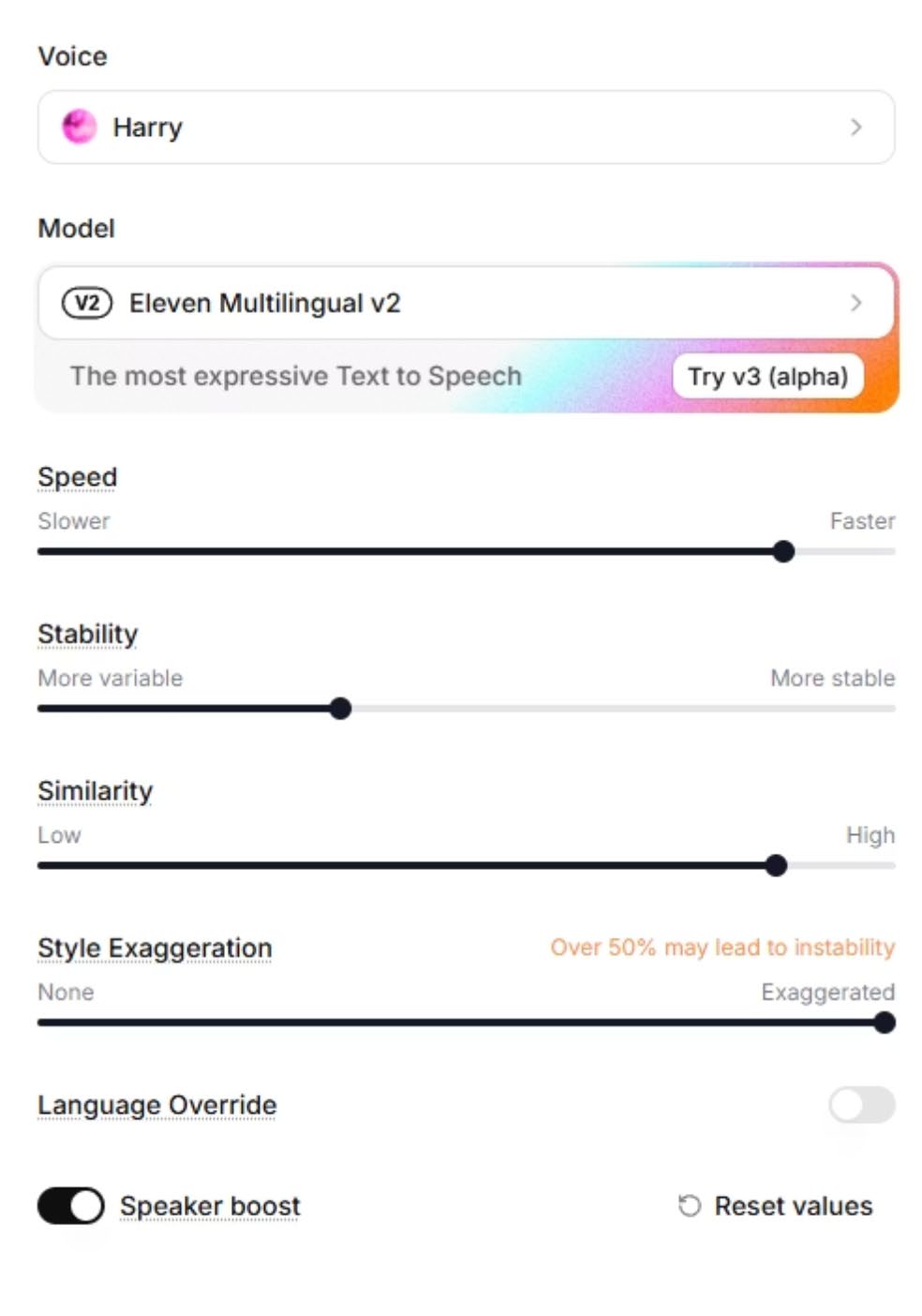
ElevenLabs was used throughout the project to create a consistent DJ narrator voice for:
- Radio-style intros
- Top-5 track announcements
- Outros and listener call-to-action prompts
- Storytelling transitions between songs
The DJ voice became a fixed element of the project's audiovisual identity.
Phase 8 — Editing in Adobe Audition
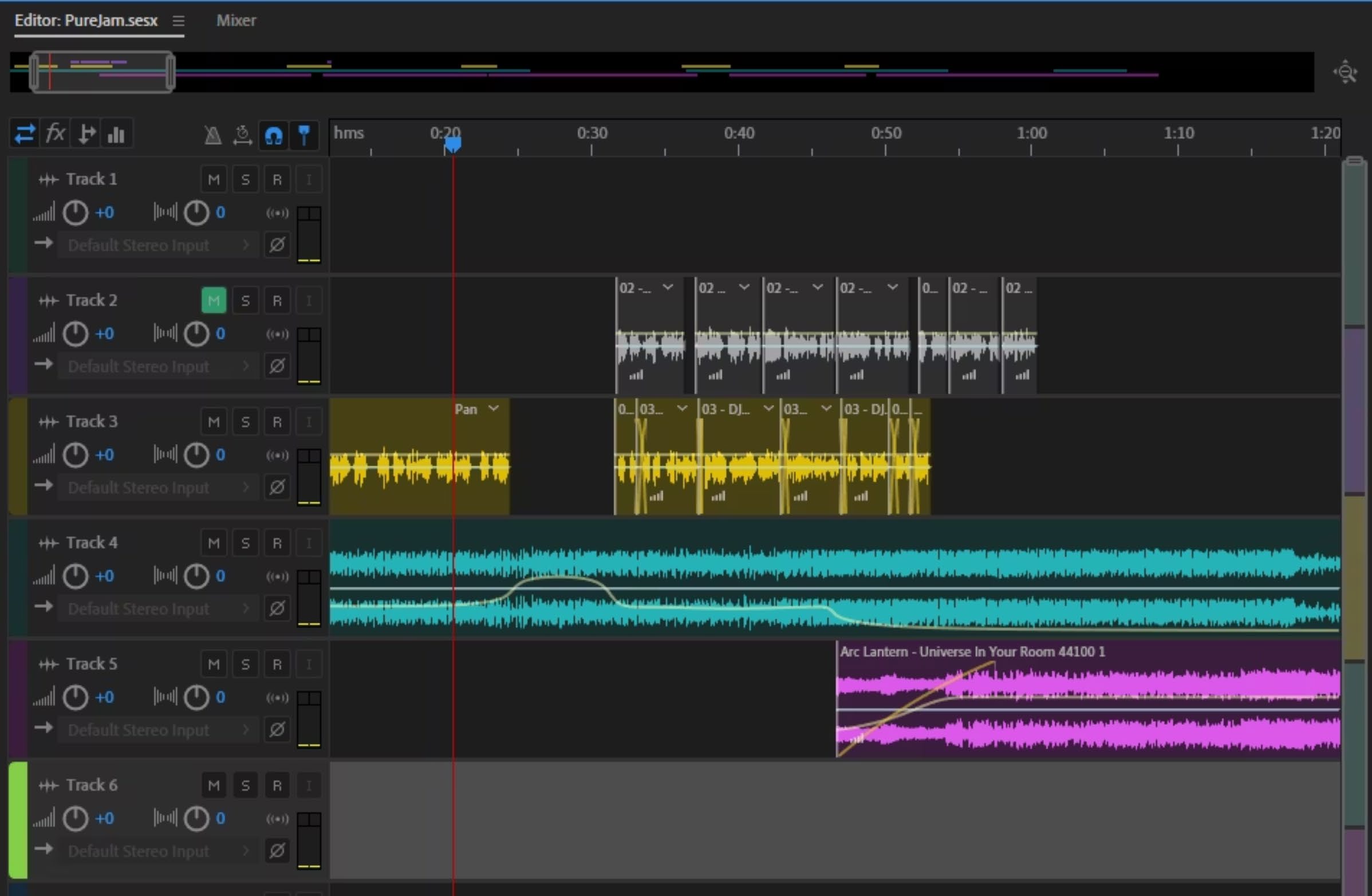
Final assembly and editing in Adobe Audition — combining generated music, separated stems, and DJ voice-over layers into a coherent finished project.
Inspiration Tracks
The project was guided by five reference tracks chosen for their range of production styles:
- Depeche Mode — World In My Eyes
- Massive Attack — Inertia Creeps
- Foo Fighters — The Pretender
- Bill Withers — Ain't No Sunshine
- Red Hot Chili Peppers — Scar Tissue
Outcome
A repeatable end-to-end AI audio production workflow: Reference analysis → Prompt system → Generation → Stem separation → Mixing & mastering → Voice-over → Final edit.
Key takeaways:
- Structured prompt tags (
[Intro],[Chorus], etc.) consistently improved musical clarity - BPM values are a soft guide in Suno — style and mood tags are more reliable controls
- Stem separation with FADR unlocks post-generation editing that pure AI output cannot provide
- A consistent voice persona (DJ narrator) significantly elevates the audiovisual identity of a project