Kontext
Dieses Projekt wurde im Rahmen des KIAUMU-Programms entwickelt. Ziel: KI-Musiktools verstehen und anwenden, um den Klang, die Stimmung und den Produktionsstil eines Referenztracks nachzubilden — und einen originellen Track zu liefern, der von „Demo" zu Studio-Mastering-Qualität führt.
Verwendete Tools: Sonoteller.ai · Suno · FADR · ElevenLabs · Adobe Audition
Kernziele:
- Reverse Engineering eines Referenztracks mittels KI-Analyse
- Prompts über Genres, Stimmungen und Instrumentierungen hinweg entwickeln und testen
- Mehrere Track-Varianten generieren, dann durch Stem-Separation, Mixing und Mastering verfeinern
- Eine konsistente DJ-Erzählerstimme für alle Lieferungen erstellen
Phase 1 — Reverse Engineering des Referenztracks

Jeder Track hat eine Struktur, die dekodiert werden kann. Mit Sonoteller.ai wurde der Referenztrack entlang von sechs Dimensionen zerlegt:
- Struktureller Zusammenbruch — Songsektionen, Übergänge, Arrangement
- Stimmung + lyrische Themen — emotionaler Bogen, lyrischer Ton
- Tempo und rhythmisches Gefühl — BPM, Groove, Swing
- Energiekurve — Aufbau, Drop, Entladungspunkte
- Instrumenten-Layers — Lead, Rhythmus, Textur, Bass, Percussion
- Stimmcharakter — Timbre, Register, Stil
Sonoteller.ai Analyseergebnis
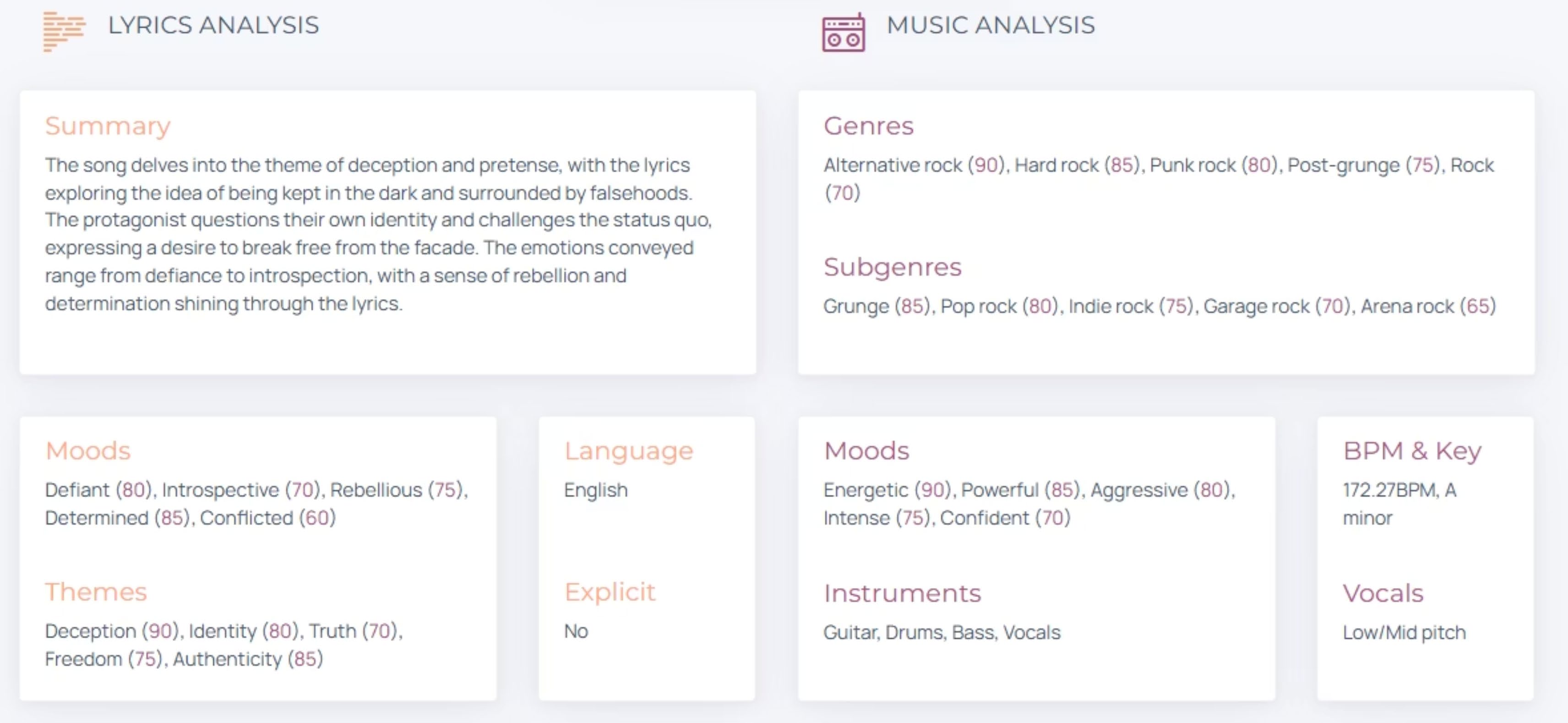
Der Analyse-Output lieferte eine strukturierte Aufschlüsselung, die direkt als Grundlage für das Suno-Prompt-System in Phase 2 diente.
Phase 2 — Prompt-Design
Es entstanden mehrere verschiedene Lieder — jedes mit bewusst variierenden Parametern:
Getestete Variablen pro Track:
- Genres — Rock, Softrock, Trip-Hop, Blues, elektronisch inspirierte Musik
- Stimmungen — dark, dreamy, melancholic, energetic, calm
- Instrumentierung — verzerrte Gitarre, warmer Bass, sanfte Drums, Klavier, Ambient-Synthesizer, Percussion
- Stimmtypen — dunkler männlicher Bariton, emotionaler männlicher Hauptdarsteller, sanfte weibliche Stimme, zarte weibliche Stimme
- Tempo — 90, 120, 122 BPM getestet (Hinweis: Suno hält sich nicht immer strikt an die BPM-Vorgabe — Struktur- und Stil-Tags erwiesen sich als zuverlässiger)
Gemeinsame Prompt-Struktur in allen Tracks:
| Tag-Typ | Elemente |
|---|---|
| Struktur | [Intro] [Strophe] [Refrain] [Bridge] [Outro] |
| Stimmung | dark, atmospheric, soft, warm, emotional, dreamy, nostalgic |
| Instrumente | verzerrte Gitarre, warmer Bass, sanfte Drums, Klavier, Ambient-Synthesizer |
| Stimmidentität | dunkler männlicher Bariton / sanfte weibliche Stimme / emotionaler männlicher Lead |
Phase 3 — Musikgenerierung mit Suno
Gemeinsame Produktionsziele in allen generierten Tracks:
- Höhere Produktionsqualität erzielen — das Gefühl eines „Demo-Tapes" vermeiden
- Klarer Gesang, ausgewogene Instrumente, stimmige Struktur
- Emotionale Übereinstimmung zwischen Text und Musik wahren
Wichtigste Beobachtungen aus der Generierung:
- Spezifischere Eingabeaufforderungen führen zu konsistenteren Ergebnissen
- Songtexte sollten kurz und ausdrucksstark sein
- Instrumentenbezeichnungen beeinflussen Groove und Stil maßgeblich
- Stimmungsbeschreibungen verändern Harmonie und Energie dramatisch
Phase 4 — Stem-Separation (FADR)
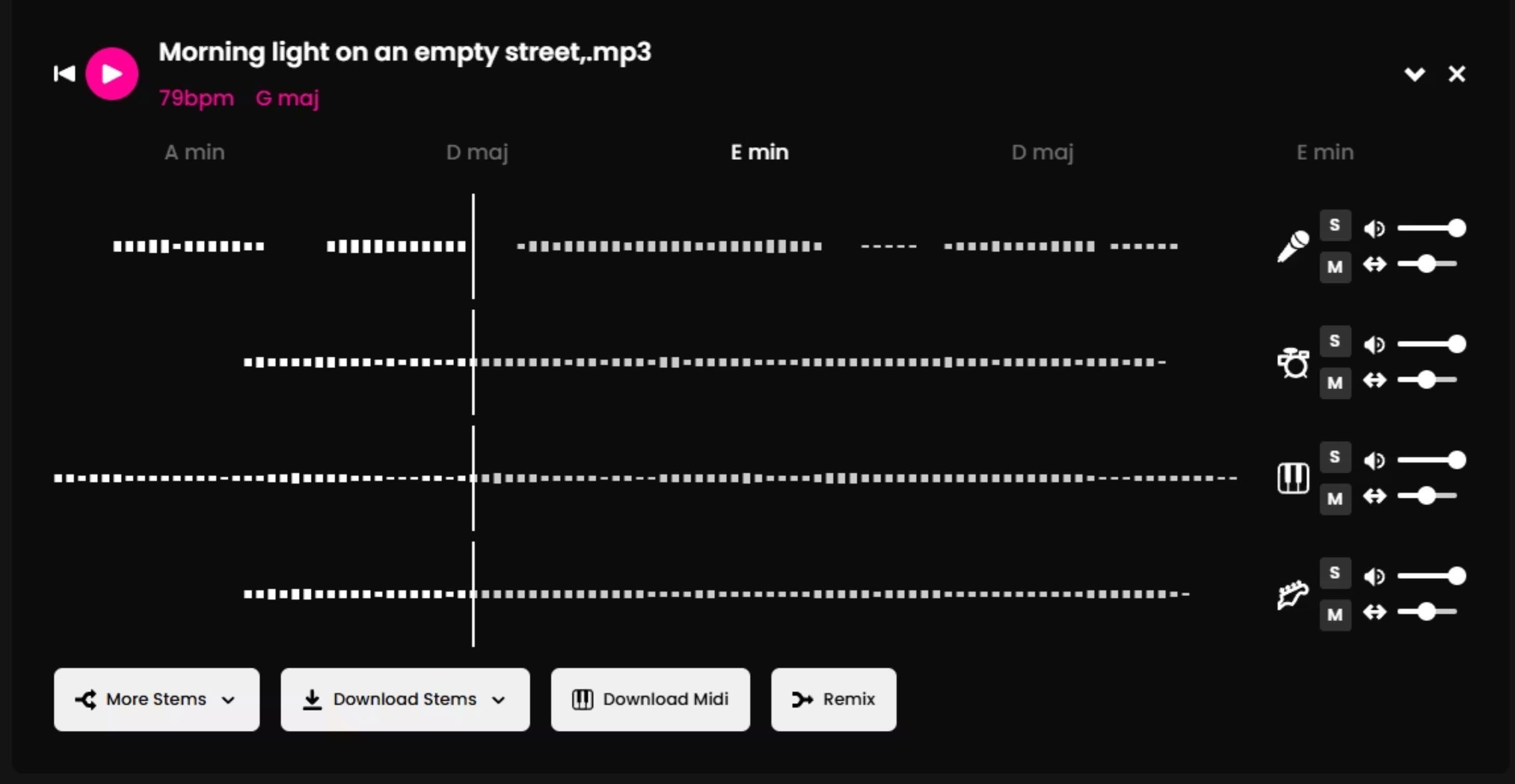
Die generierten Tracks wurden durch FADR für die Stem-Separation verarbeitet — Gesang, Drums, Bass und melodische Elemente wurden isoliert. Dies ermöglichte gezielte Anpassungen, ohne den Gesamtmix zu beeinflussen.
Phase 6 — Mixing und Mastering
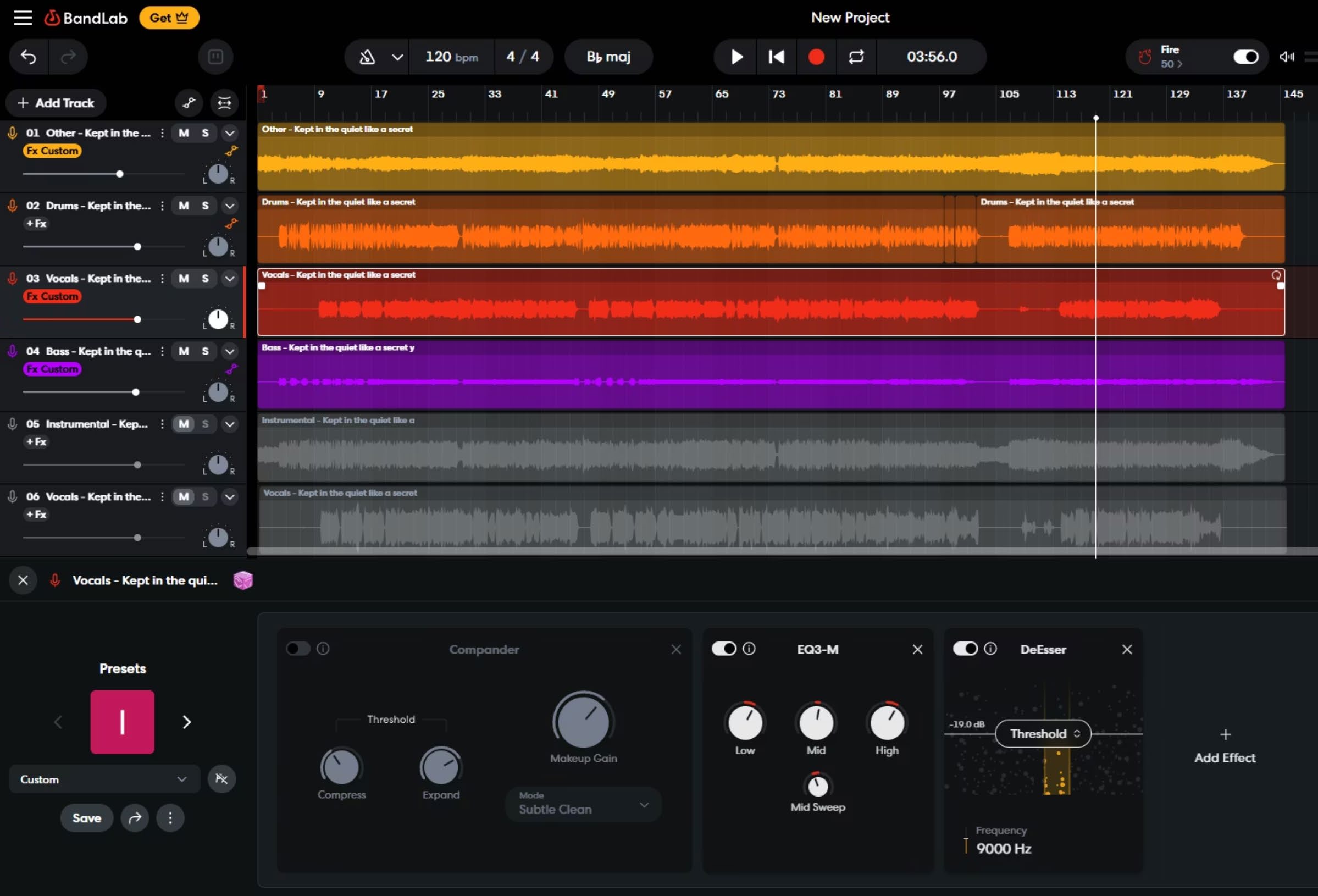
Die einzelnen Stems wurden reassembliert und verarbeitet, um Studio-Mastering-Qualität zu erreichen. Das Mixing adressierte Balance, räumliche Platzierung und Dynamikumfang über alle Instrumenten-Layers hinweg.
Phase 7 — DJ Voice Setup
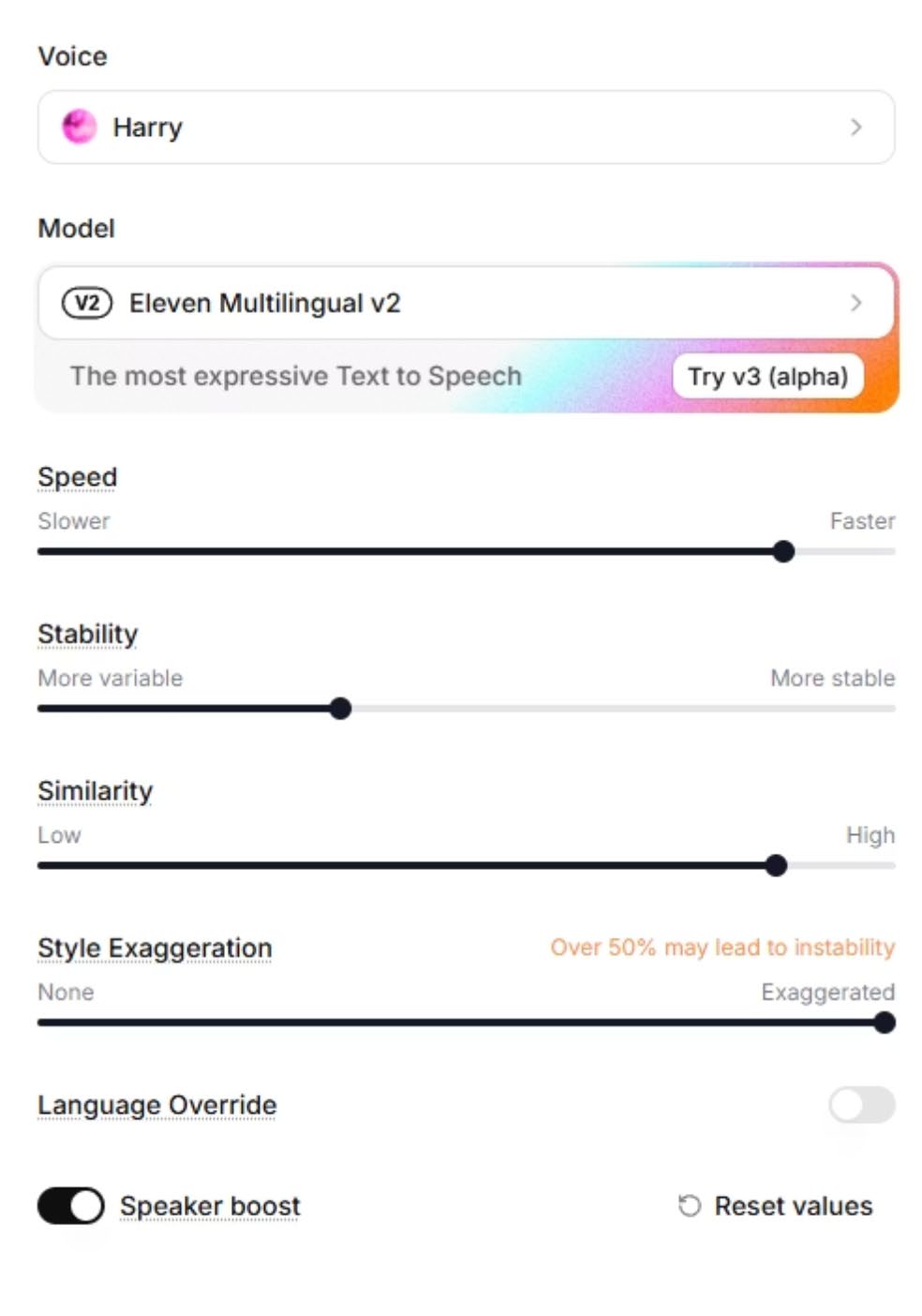
ElevenLabs wurde im gesamten Projekt eingesetzt, um eine konsistente DJ-Erzählerstimme zu erstellen für:
- Radio-ähnliche Intros
- Top-5-Ankündigungen
- Outros und Einladungen zum Abstimmen
- Storytelling-Übergänge zwischen den Songs
Die DJ-Stimme wurde zu einem festen Bestandteil der audiovisuellen Identität des Projekts.
Phase 8 — Bearbeitung in Adobe Audition
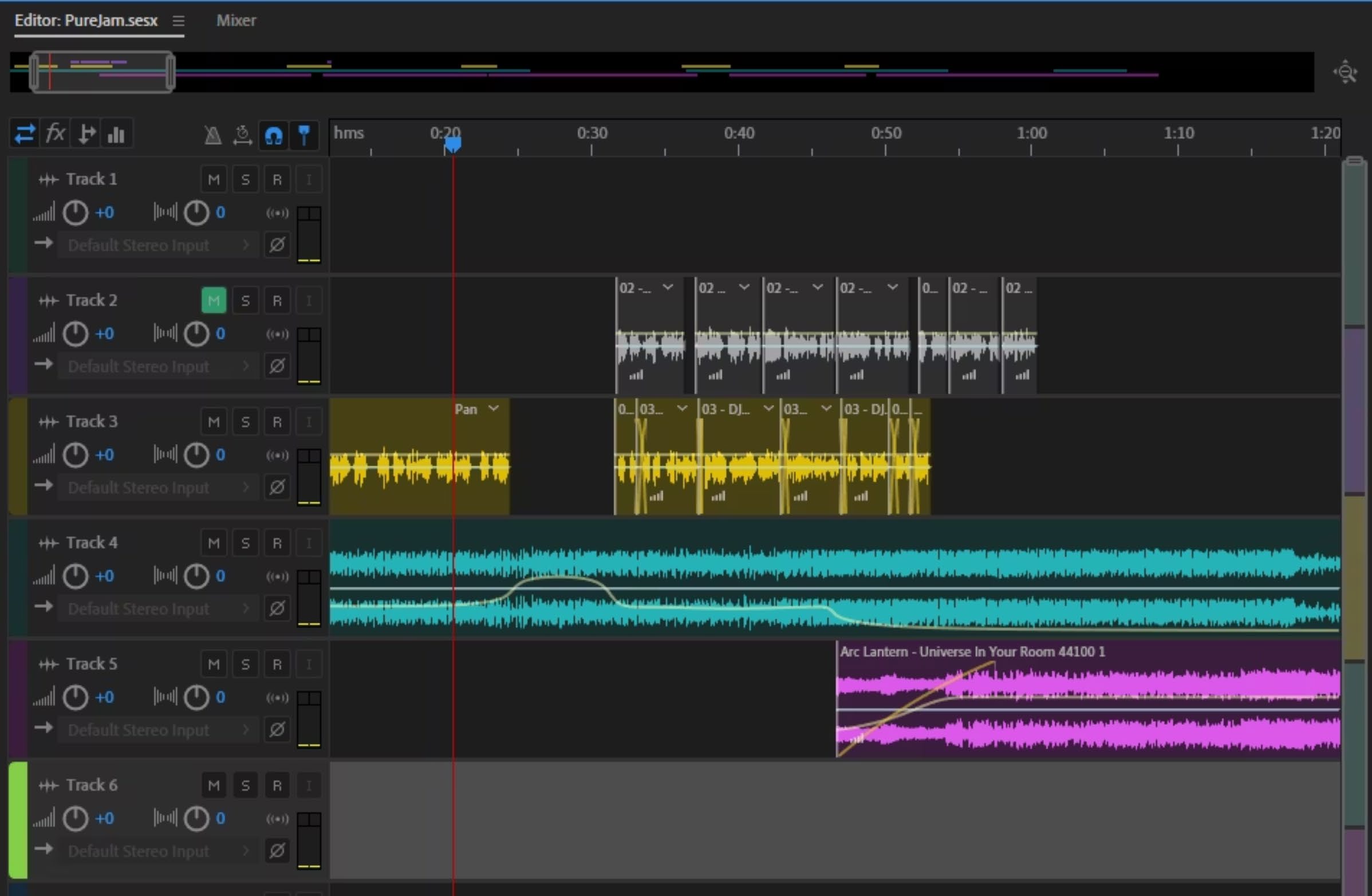
Finaler Zusammenbau und Bearbeitung in Adobe Audition — generierte Musik, separierte Stems und DJ-Voice-Over-Layer wurden zu einem kohärenten fertigen Projekt zusammengefügt.
Inspiration-Songs
Das Projekt wurde von fünf Referenztracks geleitet, ausgewählt für ihre unterschiedlichen Produktionsstile:
- Depeche Mode — World In My Eyes
- Massive Attack — Inertia Creeps
- Foo Fighters — The Pretender
- Bill Withers — Ain't No Sunshine
- Red Hot Chili Peppers — Scar Tissue
Ergebnis
Ein wiederholbarer End-to-End-KI-Audioproduktions-Workflow: Referenzanalyse → Prompt-System → Generierung → Stem-Separation → Mixing & Mastering → Voice-Over → Finaler Schnitt.
Wichtigste Erkenntnisse:
- Strukturierte Prompt-Tags (
[Intro],[Refrain]usw.) verbesserten die musikalische Klarheit durchgehend - BPM-Werte sind eine grobe Orientierung in Suno — Stil- und Stimmungs-Tags sind zuverlässigere Steuerungsmittel
- Die Stem-Separation mit FADR ermöglicht Post-Generierungs-Editing, das reiner KI-Output nicht bieten kann
- Eine konsistente Stimmpersona (DJ-Erzähler) steigert die audiovisuelle Identität eines Projekts erheblich